Analyse sémantique des partis politiques francais
Introduction
Nous allons analyser le contenu texte de 3 partis politiques francais pour voir comment ils diffèrent. Nous pourrons observer : les réseaux lexicaux, les sentiments, les sujets abordés. À la fin, cela nous permettra d’envisager le machine learning pour reconnaitre la couleur politique des textes.
Le code source est disponible sur https://github.com/paul-chrlt/political-words
Acquisition des données : scrapping
La première étape consistera à automatiser la lecture des sites internet. Pour chacun :
- aller sur la page listant les actualités et récupérer un tableau contenant un titre, un lien.
- aller sur la page suivante et recommencer, jusqu’à avoir une quantité de liens suffisante.
- aller sur chaque lien récupéré pour récupérer les textes des articles en différenciant le corps de texte, le titre, la date de publication.
Nous allons créer 3 fonctions différentes pour analyser 3 partis. Ces fonctions ne sont pas appelées directement dans ce document pour éviter de solliciter abusivement les serveurs de ces 3 sites. Vous retrouverez le fonctionnement dans les sources : scraper_rn.R, scraper_lrm.R, scraper_eelv.R.
load('articlesRN.Rdata')
load('articlesEELV.Rdata')
load('articlesLRM.Rdata')Nettoyage
Commencons par rassembler et formater l’ensemble de ces données.
Pendant le scrapping, certaines données ont pu être en doublon, nous allons aussi nettoyer ca.
articlesRN$parti <- "RN"
articlesEELV$parti <- "EELV"
articlesLRM$parti <- "LRM"
articles <- rbind(articlesRN,articlesEELV,articlesLRM,stringsAsFactors=FALSE)
articles$articleDate <- as.Date(articles$articleDate, format = "%d %B %Y")
articles$parti <- factor(articles$parti)
articles <- unique(articles,MARGIN=1)Périodicité
Nous allons déterminer les périodes de pression selon les partis. Pour ca, nous allons créer 2 colonnes supplémentaires, correspondant aux mois et aux jours de la semaine.
library(lubridate)
articles$month <- month(articles$articleDate,label = TRUE)
library(ggplot2)
monthSeasonalityPlot <- ggplot(data = articles,aes(x=month,fill=parti)) + geom_bar(position=position_dodge2(preserve = "single")) + facet_grid(parti~.) + theme_light()
monthSeasonalityPlot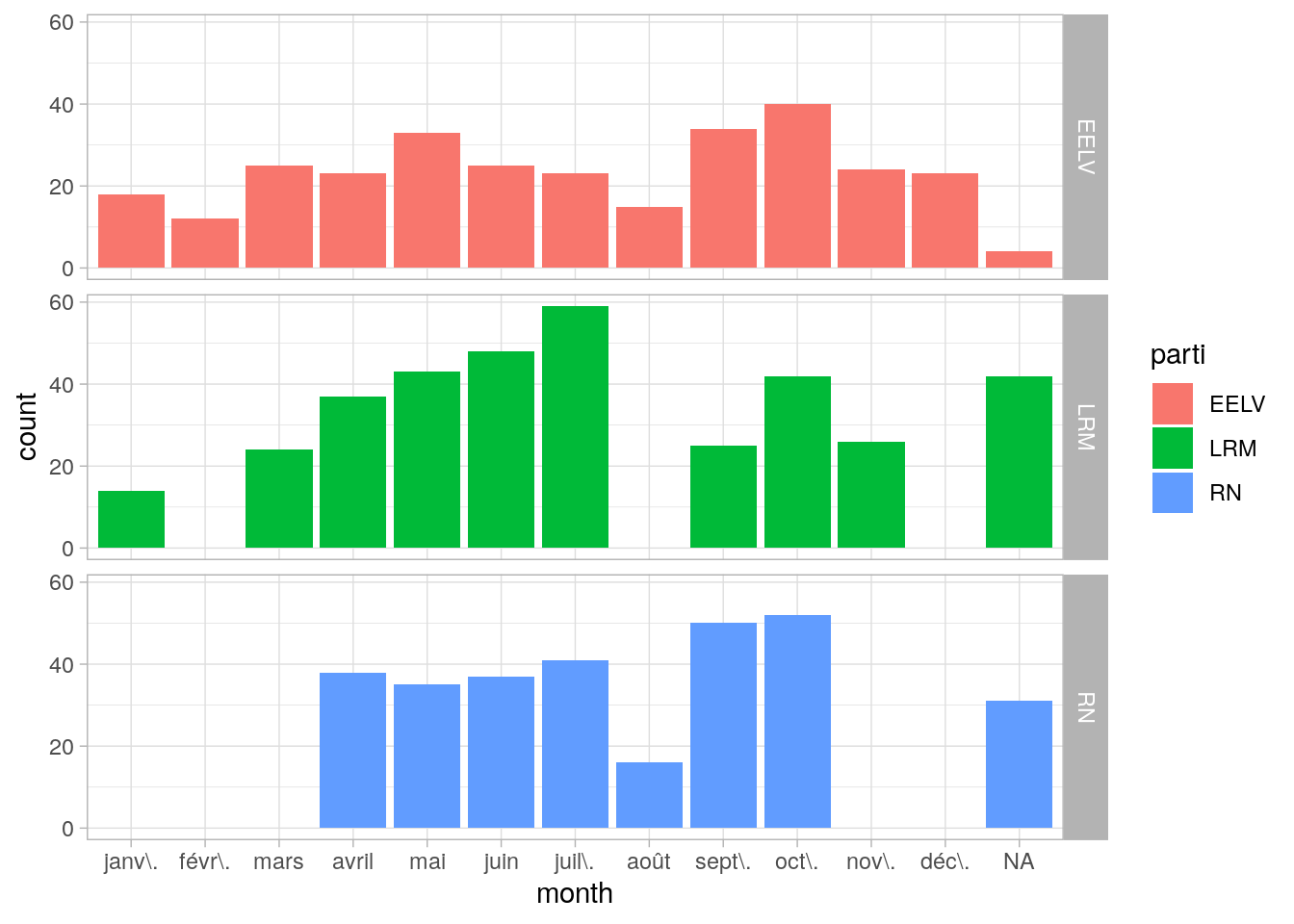
articles$day <- day(articles$articleDate)
daySeasonalityPlot <- ggplot(data = articles,aes(x=day,fill=parti)) + geom_bar(position=position_dodge2(preserve = "single")) + facet_grid(parti~.) + theme_light()
daySeasonalityPlot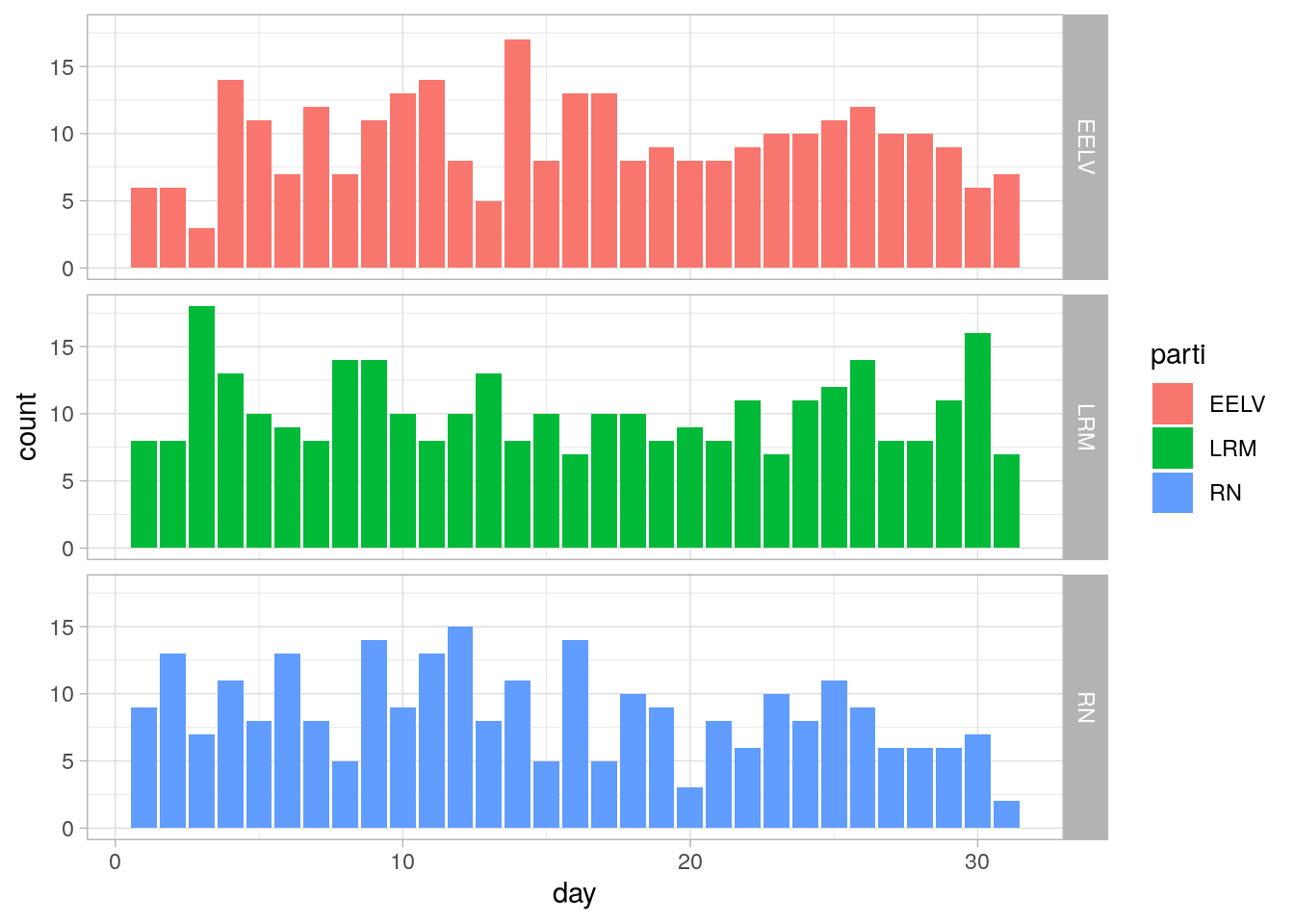
articles$weekDay <- wday(articles$articleDate,label = TRUE)
weekDaySeasonalityPlot <- ggplot(data = articles,aes(x=weekDay,fill=parti)) + geom_bar(position=position_dodge2(preserve = "single")) + facet_grid(parti~.) + theme_light()
weekDaySeasonalityPlot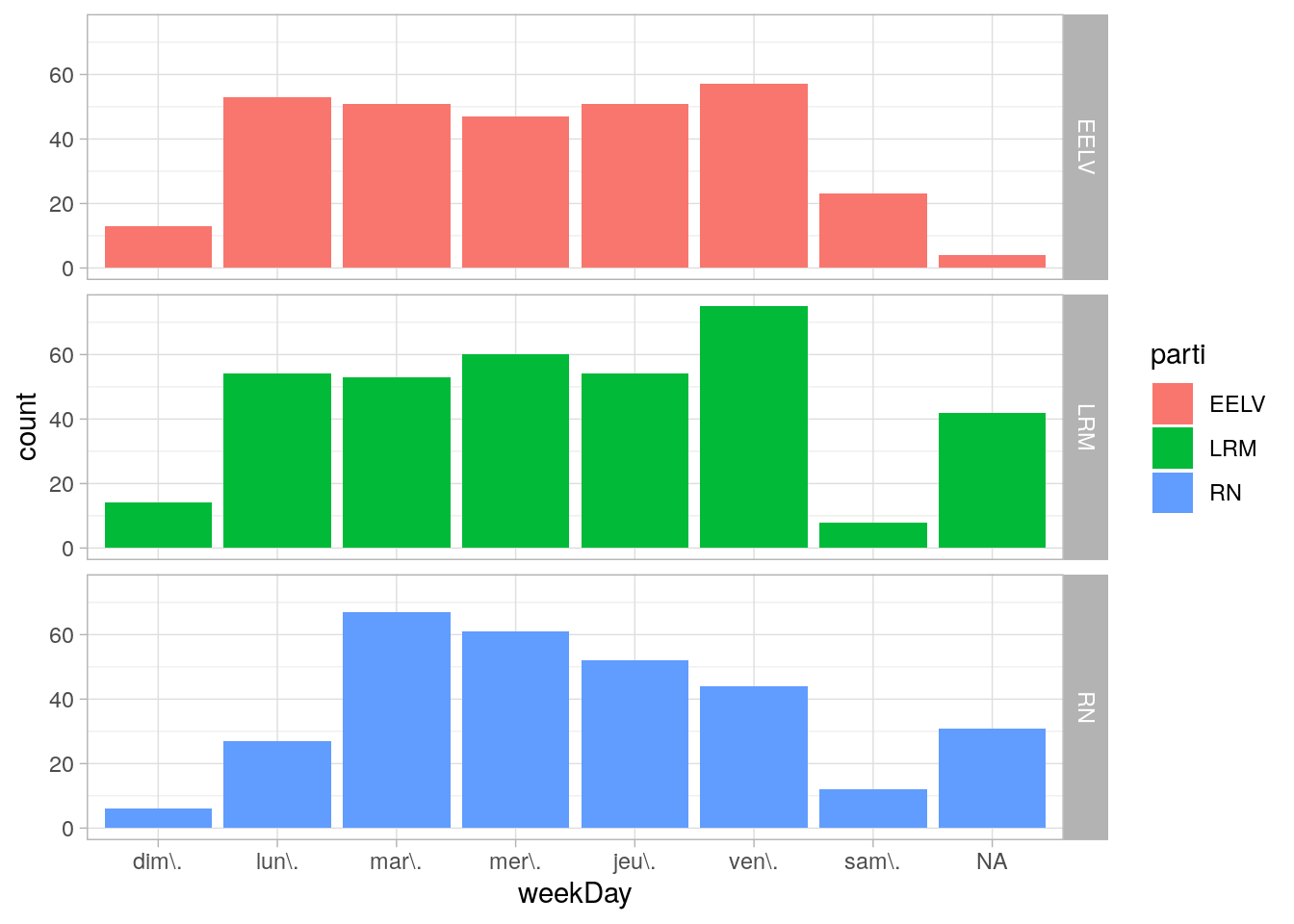
Préparation des données pour analyse NLP : UDpipe
Nous allons ensuite utiliser UDpipe pour démarrer une analyse du contenu des articles. Nous allons l’utiliser pour identifier dans nos textes :
- le radical de chaque mot : pour que les accords et la conjugaison ne perturbent pas l’analyse
- la fonction grammaticale de chaque mot : nous pourrons par exemple choisir d’exclure les prépositions
Il faudra lui fournir un modèle correspondant à la langue francaise. UDpipe fournit plusieurs modèles, nous choisissons french-gsd.
library(udpipe)
library(dplyr)Il nous reste alors à préparer les données pour nos textes :
processedArticles <- udpipe(articles$articleContent,object="french-gsd")On crée aussi un dictionnaire nous permettant de faire l’équivalence entre le numéro du document et sa source :
docDictionnary <- data.frame(docID = paste0("doc",1:nrow(articles)),
source = articles$parti
)Réseaux lexicaux
Nous pouvons commencer par regarder les mots souvent présents ensembles. Cela nous permettra d’identifier de grands thèmes ou expressions. Créons la fonction viewCoocurences() qui prendra en entrée des objets UDpipe et retournera un graphique des coocurences pour ces objets.
library(cowplot)
coocurences <- list()
viewCoocurences <- function(udpipeObjects,coocLimitation=40){
for(i in 1:length(udpipeObjects)){
coocurences[[i]] <- cooccurrence(x = subset(udpipeObjects[[i]], upos %in% c("NOUN", "ADJ")),
term = "lemma",
group = c("sentence_id"),
skipgram = 4)
}
wordnetwork <- lapply(coocurences, head,coocLimitation)
wordnetwork <- lapply(wordnetwork, graph_from_data_frame)
coocGraphs <- list()
for (i in 1:length(wordnetwork)) {
coocGraphs[[i]] <- ggraph(wordnetwork[[i]], layout = "fr") +
geom_edge_link(aes(width = cooc, edge_alpha = cooc), edge_colour = "lightgreen") +
geom_node_text(aes(label = name), col = "black", size = 4) +
theme_light() +
theme(legend.position = "none") +
labs(title = paste("Cooccurrences des mots,",names(udpipeObjects[i])), subtitle = "Nouns & Adjective")
}
plot_grid(plotlist = coocGraphs, labels = "",ncol=1) + theme_void()
}
udpipeObjects <- list("Corpus complet"=processedArticles,
"EELV"=filter(processedArticles,doc_id %in% docDictionnary$docID[docDictionnary$source=="EELV"]),
"LRM"=filter(processedArticles,doc_id %in% docDictionnary$docID[docDictionnary$source=="LRM"]),
"RN"=filter(processedArticles,doc_id %in% docDictionnary$docID[docDictionnary$source=="RN"]))
viewCoocurences(udpipeObjects,50)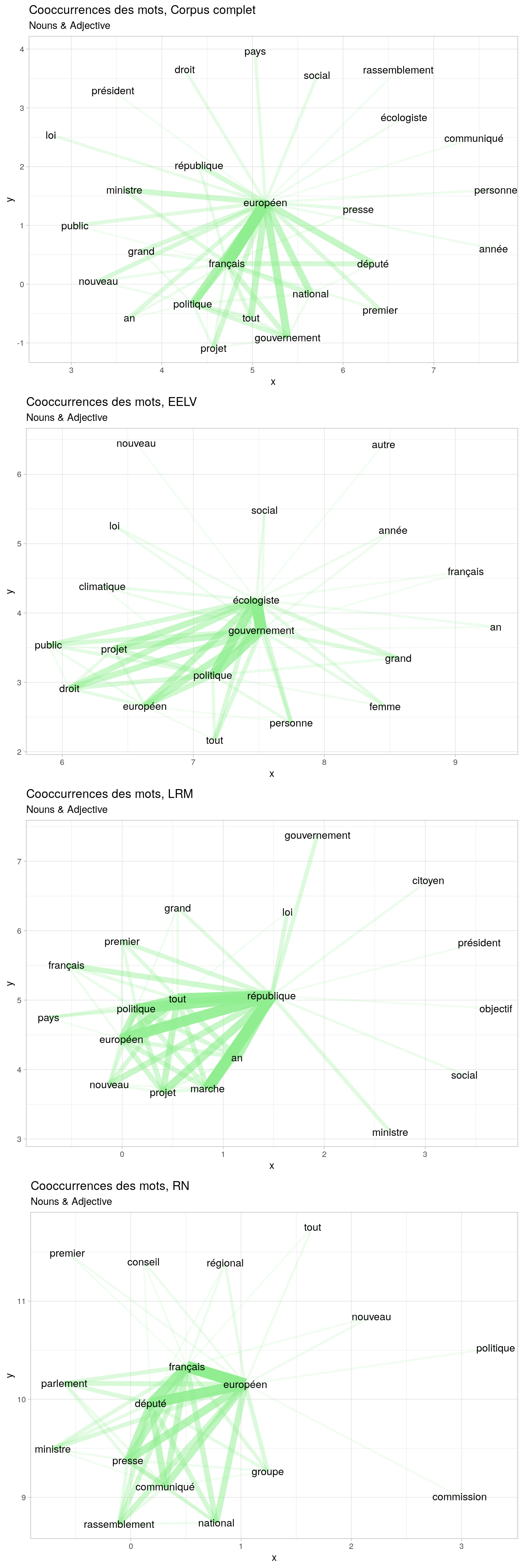
Sentiments négatifs
library(magrittr)
load(file("https://github.com/sborms/sentometrics/raw/master/data-raw/FEEL_fr.rda"))
load(file("https://github.com/sborms/sentometrics/raw/master/data-raw/valence-raw/valShifters.rda"))
sentimentsGraph <- function(udpipedText, graphTitle){
polarity_terms <- rename(FEEL_fr, term = x, polarity = y)
polarity_negators <- subset(valShifters$valence_fr, t == 1)$x
polarity_amplifiers <- subset(valShifters$valence_fr, t == 2)$x
polarity_deamplifiers <- subset(valShifters$valence_fr, t == 3)$x
sentiments <- txt_sentiment(udpipedText, term = "lemma",
polarity_terms = polarity_terms,
polarity_negators = polarity_negators,
polarity_amplifiers = polarity_amplifiers,
polarity_deamplifiers = polarity_deamplifiers)
sentiments <- sentiments$data
reasons <- sentiments %>%
cbind_dependencies() %>%
select(doc_id, lemma, token, upos, sentiment_polarity, token_parent, lemma_parent, upos_parent, dep_rel) %>% filter(sentiment_polarity < 0)
reasons <- filter(reasons, dep_rel %in% "amod")
word_cooccurences <- reasons %>%
group_by(lemma, lemma_parent) %>%
summarise(cooc = n()) %>%
arrange(-cooc)
vertices <- bind_rows(
data_frame(key = unique(reasons$lemma)) %>% mutate(in_dictionary = if_else(key %in% polarity_terms$term, "in_dictionary", "linked-to")),
data_frame(key = unique(setdiff(reasons$lemma_parent, reasons$lemma))) %>% mutate(in_dictionary = "linked-to"))
cooc <- head(word_cooccurences, 50)
set.seed(123456789)
graphicLexicalNetworks <- cooc %>%
graph_from_data_frame(vertices = filter(vertices, key %in% c(cooc$lemma, cooc$lemma_parent))) %>%
ggraph(layout = "fr") +
geom_edge_link0(aes(edge_alpha = cooc, edge_width = cooc)) +
geom_node_point(aes(colour = in_dictionary), size = 5) +
geom_node_text(aes(label = name), vjust = 1.8, col = "darkgreen") +
ggtitle(graphTitle) +
theme_void()
graphicLexicalNetworks
}
sentimentsGraph(udpipeObjects[[2]],"réseaux lexicaux à EELV dans les phrases analysées comme négatives")
sentimentsGraph(udpipeObjects[[3]],"réseaux lexicaux à LRM dans les phrases analysées comme négatives")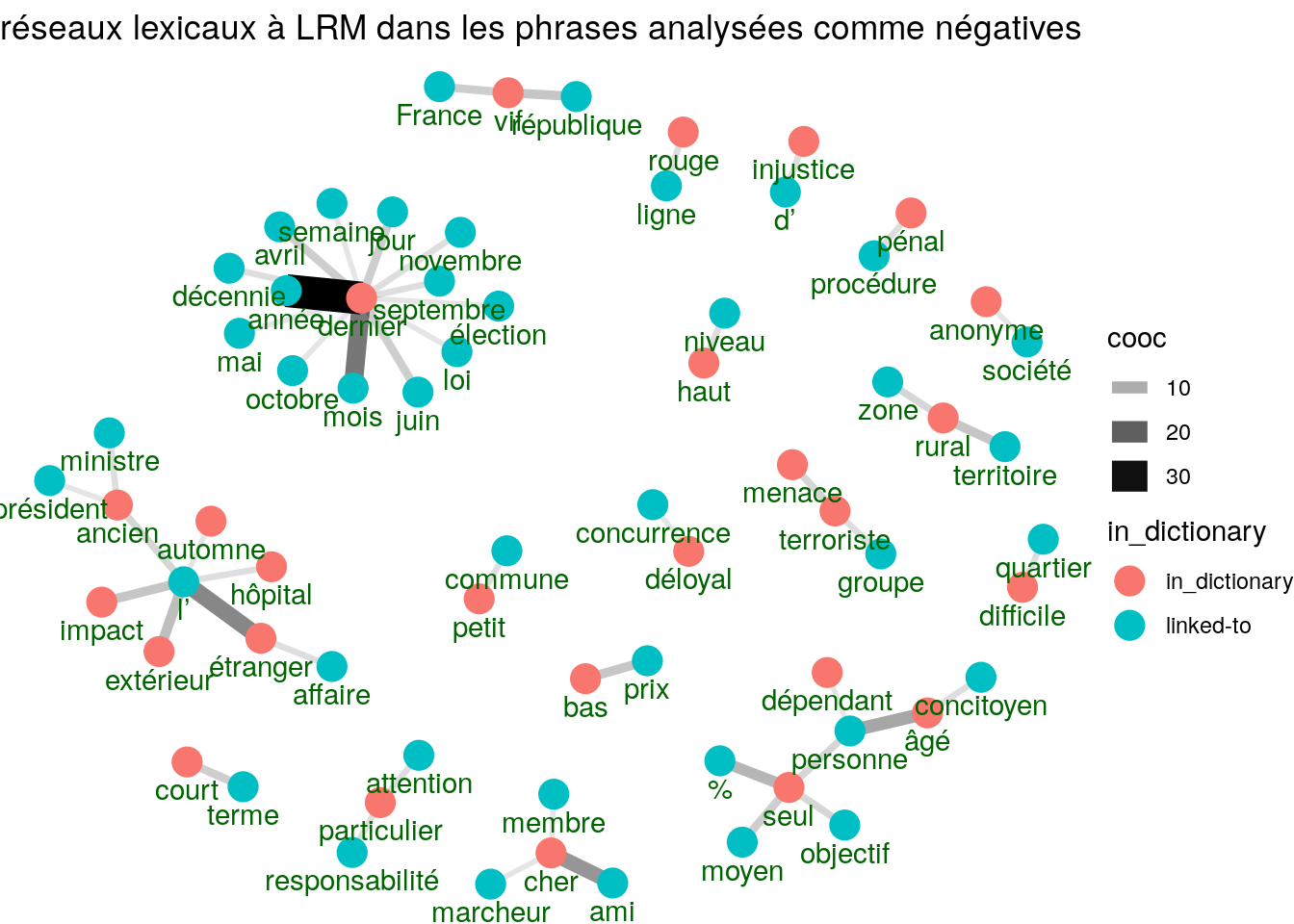
sentimentsGraph(udpipeObjects[[4]],"réseaux lexicaux à RN dans les phrases analysées comme négatives")
Analyse des sujets
La librairie text2vec contient l’implémantation de l’algorithme LDA (Latent Dirichlet Allocation). Nous avons 3 hyperparamètres :
- le nombre de sujets à extraire. Arbitrairement, nous en extraierons 6.
- la propension à avoir peu de sujets par document
- la propension à avoir peu de mots par sujet
dtf <- document_term_frequencies(filter(processedArticles,upos %in% c("ADJ","NOUN")),"doc_id","lemma")
dtm <- document_term_matrix(dtf)
library(text2vec)
lda_model <- LDA$new(n_topics = 6, doc_topic_prior = 0.1, topic_word_prior = 0.01)
subjects <- lda_model$fit_transform(x = dtm, n_iter = 1000, convergence_tol = 0.001, n_check_convergence = 25, progressbar = FALSE)## INFO [2019-12-08 23:49:05] iter 25 loglikelihood = -875753.915
## INFO [2019-12-08 23:49:06] iter 50 loglikelihood = -859130.850
## INFO [2019-12-08 23:49:06] iter 75 loglikelihood = -854183.629
## INFO [2019-12-08 23:49:06] iter 100 loglikelihood = -851513.515
## INFO [2019-12-08 23:49:07] iter 125 loglikelihood = -850606.185
## INFO [2019-12-08 23:49:07] iter 150 loglikelihood = -851236.147
## INFO [2019-12-08 23:49:07] early stopping at 150 iterationtopWords <- lda_model$get_top_words(n = 10,lambda = 0.3)
kable(topWords)| député | pays | république | violence | social | climatique |
| européen | monde | marche | femme | réforme | écologiste |
| régional | peuple | mouvement | animal | système | agricole |
| groupe | histoire | projet | victime | besoin | transition |
| parlement | migrant | débat | droit | choix | écologique |
| municipal | souveraineté | politique | police | jeune | écologie |
| rassemblement | commun | citoyen | parole | formation | agriculteur |
| conseiller | guerre | élection | loi | école | environnemental |
| commission | frontière | idée | sexuel | société | produit |
| liste | mot | local | terrorisme | défi | nucléaire |
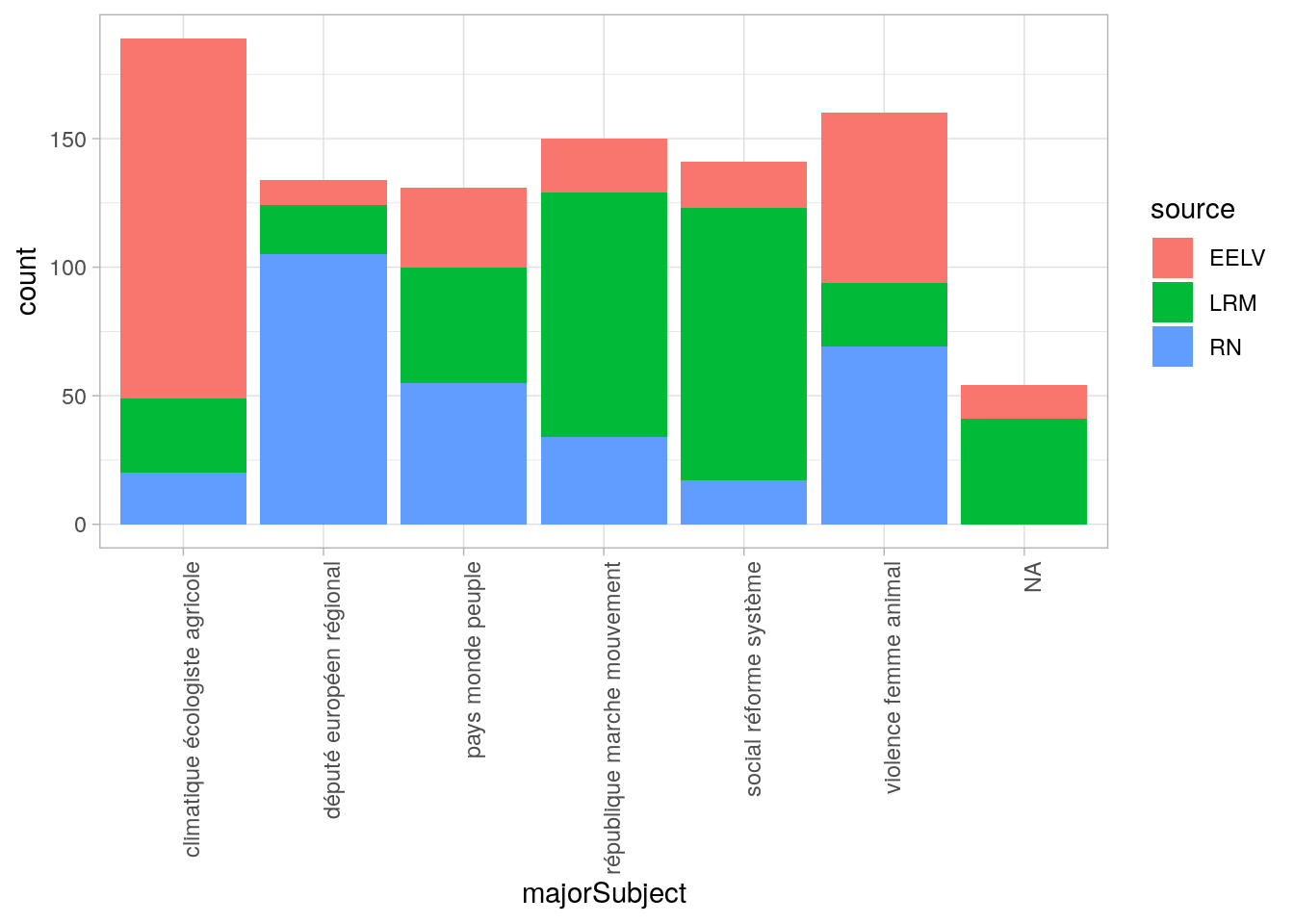
On distingue quelques sujets :
- l’écologie
- l’agriculture
- la campagne politique
- l’europe
- la souveraineté nationale
Voyons leur représentation selon les sources de texte.
subjects <- data.frame(doc_id = rownames(subjects),subjects)
docDictionnary <- left_join(docDictionnary,subjects,by=c("docID"="doc_id"))
subjectNames <- apply(
topWords[1:3,],
2,
paste,
collapse=" "
)
docDictionnary$majorSubject <- character(length = nrow(docDictionnary))
for(i in 1:nrow(docDictionnary)){
if(anyNA(docDictionnary[i,3:8])){docDictionnary$majorSubject[i] <- NA}else{
docDictionnary$majorSubject[i] <- subjectNames[which.max(docDictionnary[i,3:8])]
}
}
subjectsPlot <- ggplot(docDictionnary,aes(majorSubject,fill=source)) + geom_bar() + theme_light() + theme(axis.text.x = element_text(angle = 90, hjust = 1))
subjectsPlot